A short new paper by Steven T. Piantadosi of the University of Rochester has some interesting implications for the types of behavioral modeling that currently drives so much of the technology in the news these days, from targeted advertising to social media manipulations to artificial intelligence. The paper, entitled “One parameter is always enough,” shows that a single, alarmingly simple function–involving only sin and exponentiation on a single parameter–can be used to fit any data scatterplot. The function, if you’re interested, is:
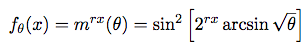
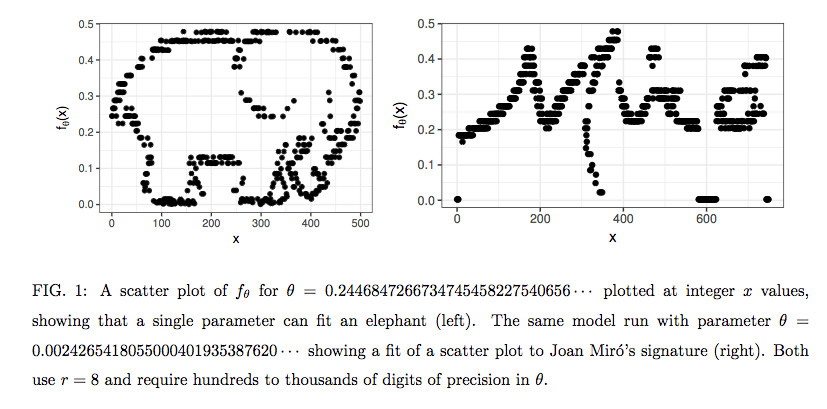
Dr. Piantadosi illustrates the point with humor by finding the value of the parameter (θ) in his equation for scatterplots of an elephant silhouette and the signature of Joan Miró:
The implications of this result for our big-data-churning, AI-hunting society are complex. For those involved in creating algorithmic models based on statistical analysis of complex datasets, the paper counsels humility and even skepticism in the hunt for the most parsimonious and elegant solutions: “There can be no guarantees about the performance of [the identified function] in extrapolation, despite its good fit. Thus, … even a single parameter can overfit the data, and therefore it is not always preferable to use a model with fewer parameters.” (p. 4) Or, as Alex Tabarrok puts it: “Occam’s Razor is wrong.” That is, simplicity is not necessarily a virtue of algorithmic models of complex systems: “models with fewer parameters are not necessarily preferable even if they fit the data as well or better than models with more parameters.”
For non-human modelers–that is, for “machine learning” projects that hope to make machines smarter by feeding them more and more data–the paper offers us good reason to think that human intervention is likely to remain extremely important, both in interpreting the data and in constructing the learning exercise itself. As Professor Piantadosi puts it: “great care must be taken in machine learning efforts to discover equations from data since some simple models can fit any data set arbitrarily well.” (p. 1), and AI designers must continue to supply “constraints on scientific theories that are enforced independently from the measured data set, with a focus on careful a priori consideration of the class of models that should be compared.” (p. 5) Or, as Kevin Drum puts it: “A human mathematician is unlikely to be fooled by this, but a machine-learning algorithm could easily decide that the best fit for a bunch of data is an equation like the one above. After all, it works, doesn’t it?”
For my part, I’ll only add that this paper is just a small additional point in support of those lawyers, policymakers, and scholars–such as Brett Frischmann, Frank Pasquale, and my soon-to-be colleague Kate Klonick–who warn that the increased automation and digitization of our lives deserves some pushback from human beings and our democratic institutions. These scholars have argued forcefully for greater transparency and accountability of the model-makers, both to the individuals who are at once the data inputs and, increasingly the behavioral outputs of those models, and to the institutions by which we construct the meaning of our lives and build plans to put those meanings into practice. If those meanings are–as I’ve argued–socially constructed, social processes–human beings consciously and intentionally forming, maintaining, and renewing connections–will remain an essential part of making sense of an increasingly complex and quantified world.


