I arrived in Tokyo two days ago, and have already begun work at the Institute of Intellectual Property, digging in to the Japan Patent Office’s (JPO’s) trademark registration data. I’ve worked with several countries’ intellectual property data systems by now, and I’m starting to think they may provide a window into the societies that produced them–though I’m still too jet-lagged to thoughtfully analyze the connection. Besides which, any analysis purporting to draw such a connection would inevitably be reductive and probably chauvinistic. So, purely by way of observation:
The US Patent and Trademark Office, for several years, has maintained and published its bulk data in XML format–open, modern, flexible, and widely adopted. It got Google to host the data, gratis, for distribution to the public via the Internet. It then got the stable of economists it keeps on staff to clean up the data and re-distribute them in two additional formats–one proprietary, one open–more convenient for researchers, complete with an open-access research paper detailing the contents.
As of a year ago, Canada’s trademark registration system relied on a COBOL database in which all information in the system was jammed into a flat, rectilinear structure with rows of exactly 98 characters. COBOL was already outdated in the 80s, but it still works, it would be cumbersome and expensive to replace, and let’s face it: how many people are likely to get worked up over the modernity of the Canadian trademark registry’s computer system? (N.B.: it appears that some time in the past year Canada may indeed have migrated to an XML format.) CIPO doesn’t distribute its bulk data via the Internet; if you’re a commercial entity, you have to buy them, and if not you have to prove your non-profit status and agree to a mildly restrictive license. When you do, Canada will send you a homemade DVD-ROM of your data.

Japan’s trademark registration system relies on a sui generis, purpose-built, multi-tiered, hierarchical file system defined by dozens of original individual SGML specifications collectively containing hundreds (possibly thousands) of tags, wherein there appears to be no correspondence between the SGML DTD filenames, the doctype names defined within those DTDs, the names of the folders containing the instances of those doctypes, or the filenames of the instances themselves. Each subtle variant on the types of information published by JPO gets its own syntax and its own dictionary. Each line of each gazette is its own document instance. This is the file structure:
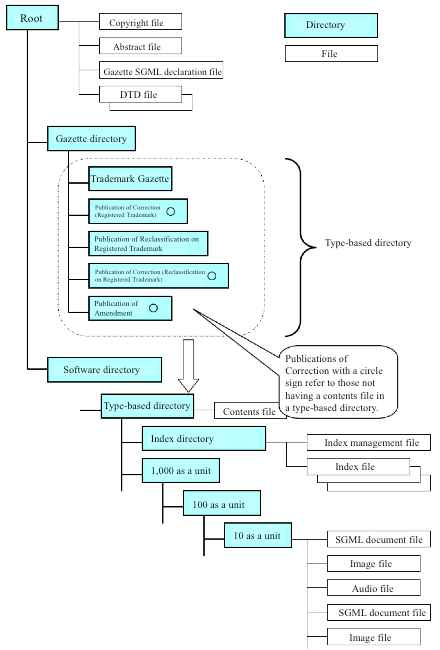
And this is an excerpt from a reference chart in the JPO’s specification for its electronic distribution of official gazettes, covering just the relationship between the gazette subfolders and the dictionaries for the files they contain:
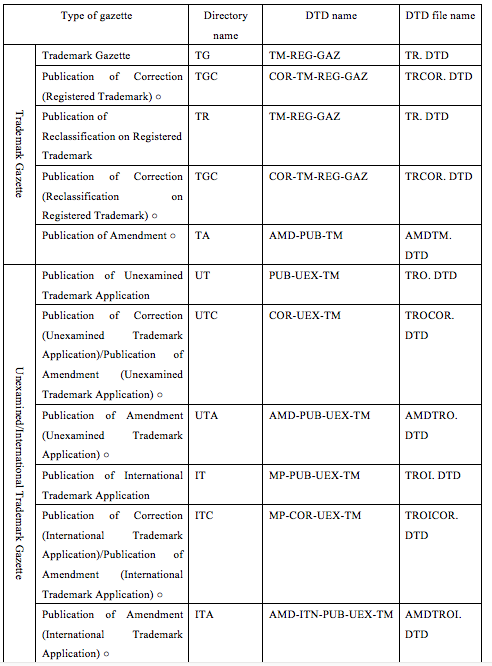
(The specification for this data is available to the public only in Japanese; I have these handsome translations due to the beneficence of my sponsors at IIP, who generously commissioned them for me.) The data themselves are not easily accessible in bulk to the public. You can download individual gazettes from the JPO as they are published (though official publication via the Internet only covers the past few years’ data). To get older data, you must obtain credentials from the National Center for Industrial Property Information and Training (INPIT)–which I understand to be a sub-agency of JPO–to gain access to their bulk data download service. Even that service requires individual downloads of individual periodic distributions, and only covers relatively recent data; for a full backfile one must make special arrangements with INPIT, which will compile bulk data for a modest cost. They’re doing that for me right now; it’s expected to take the first two of my seven weeks here just to deliver the data.
Hopefully by then I’ll have figured out how to read them.


