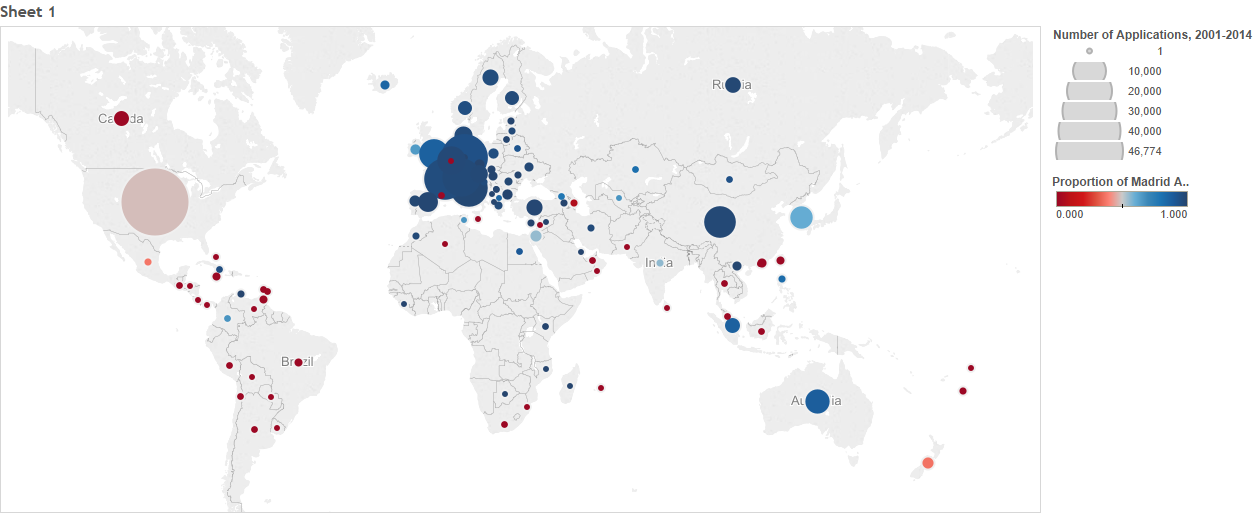
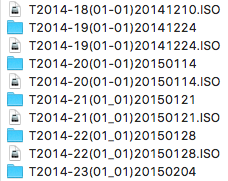
At some point in 2014, without any warning so far as I can tell, the Japan Patent Office changed the file-naming convention for their digital archives. Whereas before the archives would be stored under a filename such as “T2014-20(01-01)20150114.ISO”, hereafter they will be stored under a file name such as “T2014-21(01_01)20150121.ISO”.
 Catch the difference? Yeah, I didn’t either. Until I let my code–which was based on the old naming convention–run all day. Then I found out the last two years’ data had corrupted all my output files, wiping out 7 GB of data. More fun after the jump…
Catch the difference? Yeah, I didn’t either. Until I let my code–which was based on the old naming convention–run all day. Then I found out the last two years’ data had corrupted all my output files, wiping out 7 GB of data. More fun after the jump…
The difference is in the (01-01) part. Do you see it? JPO changed the hyphen (-) to an underscore (_). I have no idea why. I don’t think those (01-01) characters are even informative–as far as I can tell they never change. Maybe they just got bored of doing things the same way for so long.
But when your computer script parses filenames for regular patterns and one of those patterns is two two-digit numbers separated by a hyphen, and then the script uses the matching patterns to populate your data, this one-character change can literally wipe out your entire dataset. I learned that the hard way. The fix was simple–change the “-” in a regex matching command to “[-_]”. Literally a three-character patch. But it took me a couple hours to even figure out what the problem was and then pinpoint the affected commands in the hundreds of lines of code I’m working with.
Thank goodness for Dropbox’s version backups–now I only have to re-run two years’ worth of routines instead of fifteen. Seeing as how running the routines for the late years in this dataset requires pairwise comparison of over 5 GB of observations with nearly 1 GB of observations (which takes about 40 minutes), that’s something to be thankful for.