I’ve been trying for about three days to figure out why one of the scripts I was given to parse all this government data has been failing when I try to run it. Because the researchers who gave me the scripts commissioned them from some outside programmers, they can’t help me debug it. So I’ve been going line-by-line through the code and cross-referencing every command, option, and character with online manuals and forums.
My best guess is that my problem is (probably) once again a failure of translation. The code I’ve been given was written for LINUX, a (relatively) open UNIX platform. Mac OSX–which I use–is also built on top of a UNIX architecture, which power users can access via the built-in Terminal application. But Apple uses an idiosyncratic and somewhat dated version of the UNIX shell scripting language–this is the computer language you can use to tell the computer to do stuff with the files stored on it. (“Think different” indeed.) There are tons of tiny differences between Apple’s shell language and the open standard implemented in LINUX, and any one of them could be responsible for causing my code to fail. I spent the better part of two days tweaking individual characters, options, and commands in this script, to no avail. Then I tried a patch to update Apple’s scripting language to more closely mirror the one used by LINUX. Still no luck. And three days of my precious seven-week residency in Tokyo gone.
So I gave up. I’ll write my own code instead.
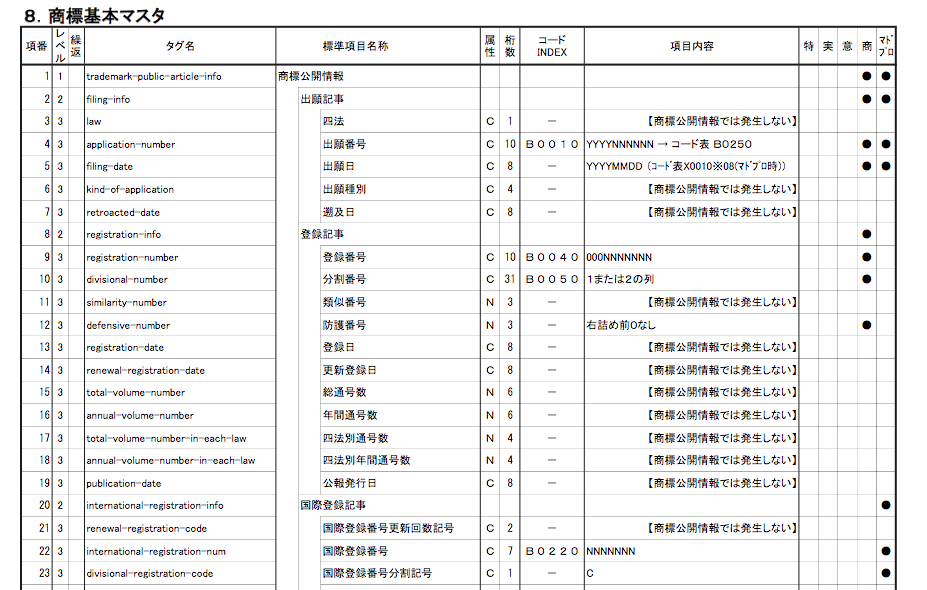
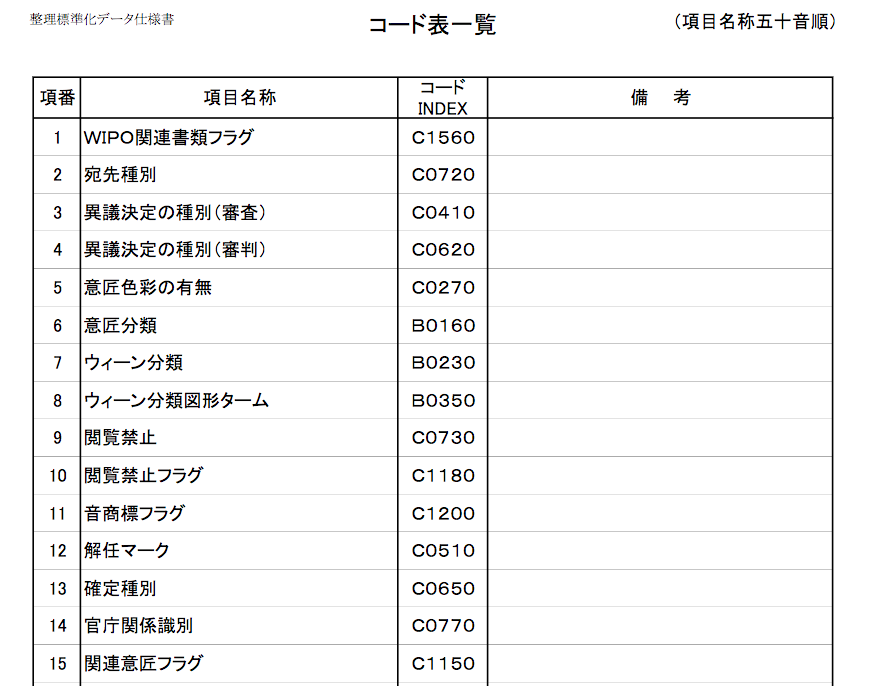
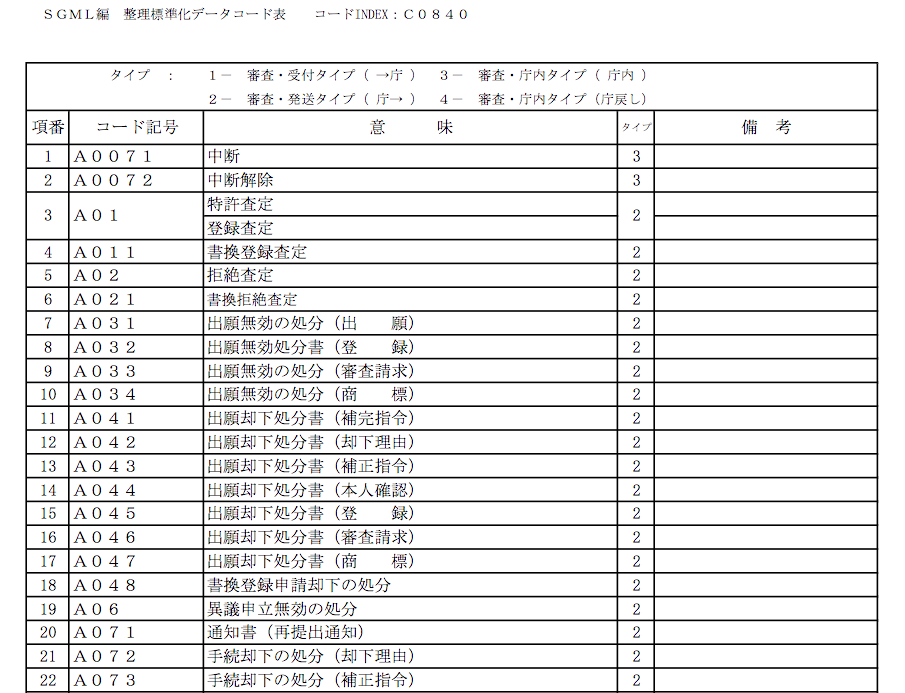
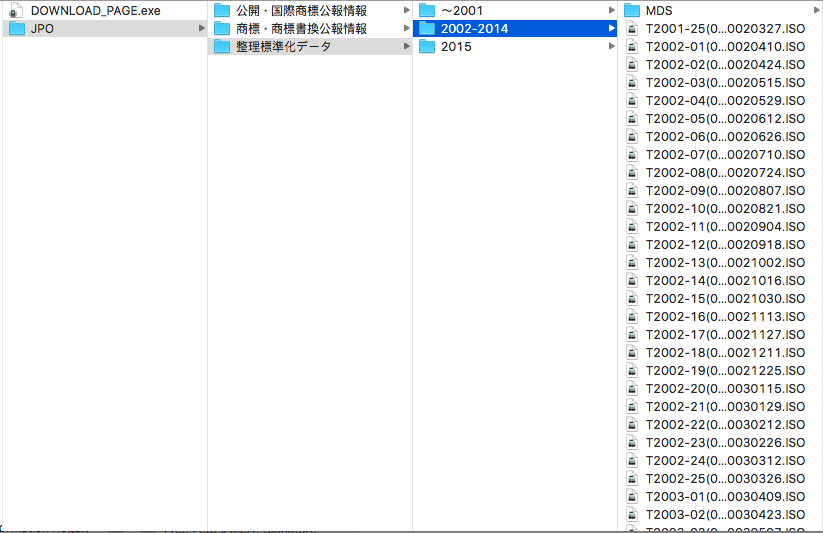
The script I’ve been trying to debug is one of a series of algorithms used to collate and deduplicate several years’ worth of parsed data. But I can create those kinds of algorithms myself, once I know how the parsed data is structured. The hard part was parsing the data in the first place to extract it from its arcane government archive format–and the scripts that do that worked a treat, once I figured out how they function. Besides which, the deduplication strategy used by the researchers who gave me these troublesome scripts is a bit more heavy-handed than I’d use if I were starting from scratch. Which I just did–in Stata, the statistical software package I’ll use to analyze the data, which uses a native scripting language I’m much more familiar with.
This new script seems to be working; now I just need a good solid stretch of time to allow my home-brewed code to process the several gigabytes of data I’m feeding it. Unfortunately, time is in short supply–I’m in week 3 of my 7-week stay, and I’m supposed to present my findings to my hosts during my last week here. So from here on out, days are for coding and nights are for processing.
It’ll get done. Somehow.