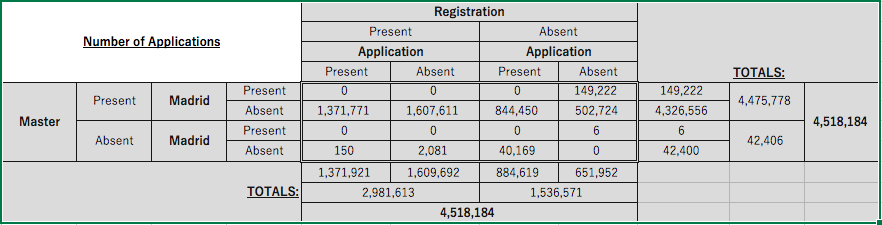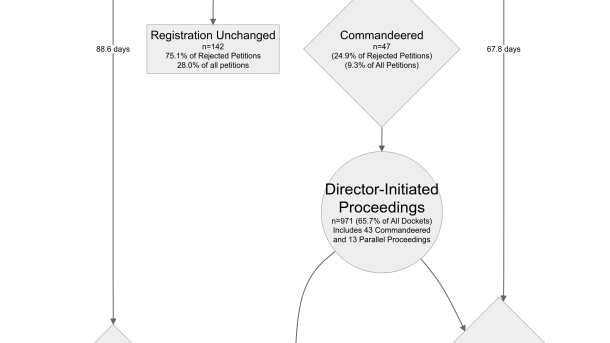
I’ve just posted to SSRN a preprint of my forthcoming article reporting the first empirical analysis of the Trademark Modernization Act’s new ex parte reexamination and expungement proceedings. The paper is accompanied by a new open-access, original dataset on all TMA dockets to date. Here’s the abstract:
The Trademark Modernization Act of 2020 (“TMA”) created two new forms of administrative proceeding designed to clear spurious trademarks from the federal register. Congress’s hope for these new proceedings was that they would “respond to concerns that registrations persist on the trademark register despite a registrant not having made proper use of the mark covered by the registration” by “allow[ing] for more efficient, and less costly and time consuming” means of removing them. This article subjects that policy to empirical examination, disclosing and analyzing a newly constructed dataset covering the dockets of all TMA proceedings (and petitions for proceedings) to date.
The results are not encouraging. Petitions to institute TMA proceedings are seldom filed, proceedings on those petitions are only sometimes instituted, the number of proceedings initiated by the United States Patent and Trademark Office (“USPTO”) sua sponte is relatively small, and the time it takes to progress from institution of a proceeding to a cancellation order is substantial. In a system where random audits of the most recently renewed registrations suggest an overall non-use rate of between 10 and 50 percent, the machinery of third-party petitions (subject to a filing fee) and ex parte review (subject to the USPTO’s overall resource constraints) appear to be a particularly inefficient means of preventing clutter on the trademark register. Based on the analysis presented herein, TMA proceedings seem, at best, to be a fairly reliable and moderately expeditious administrative pathway for clearing previously identified spurious applications from the register, but they are not likely to be a useful tool for combatting at scale the type of bad-faith trademark applications and registrations that have become so common in our age of automated, algorithmic e-commerce.
The paper, which was an invited contribution to the 2024 University of Houston Law Center Institute for Intellectual Property & Information Law National Conference in Santa Fe, is forthcoming in the Houston Law Review and available now in preprint form at SSRN. The dataset is available at Zenodo.